![[Amazon Bedrock] ナレッジベースの新機能「カスタムデータソース」と「直接取り込み (direct ingestion)」を試してみた](https://images.ctfassets.net/ct0aopd36mqt/3aqf4zA8eWdIL3CoGscPpm/224083826f6e4dd7b971c4967b706ad8/reinvent-2024-try-jp.jpg?w=3840&fm=webp)
[Amazon Bedrock] ナレッジベースの新機能「カスタムデータソース」と「直接取り込み (direct ingestion)」を試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
みなさん、こんにちは!
福岡オフィスの青柳です。
re:Invent 2024にて、Amazon Bedrock Knowledge Basesの「カスタムデータソース」と「直接取り込み (direct ingestion)」が発表されました。
速報は下記ブログ記事をご覧ください。
今回は、これらの新機能について深掘りしつつ検証したいと思います。
「カスタムデータソース」とは
まず、新機能のうち「カスタムデータソース」(あるいは「カスタムコネクタ」) について、どのようなものか確認します。
従来から用意されている「S3データソース」などの各種データソースは、下図のような構成・動作となっています。
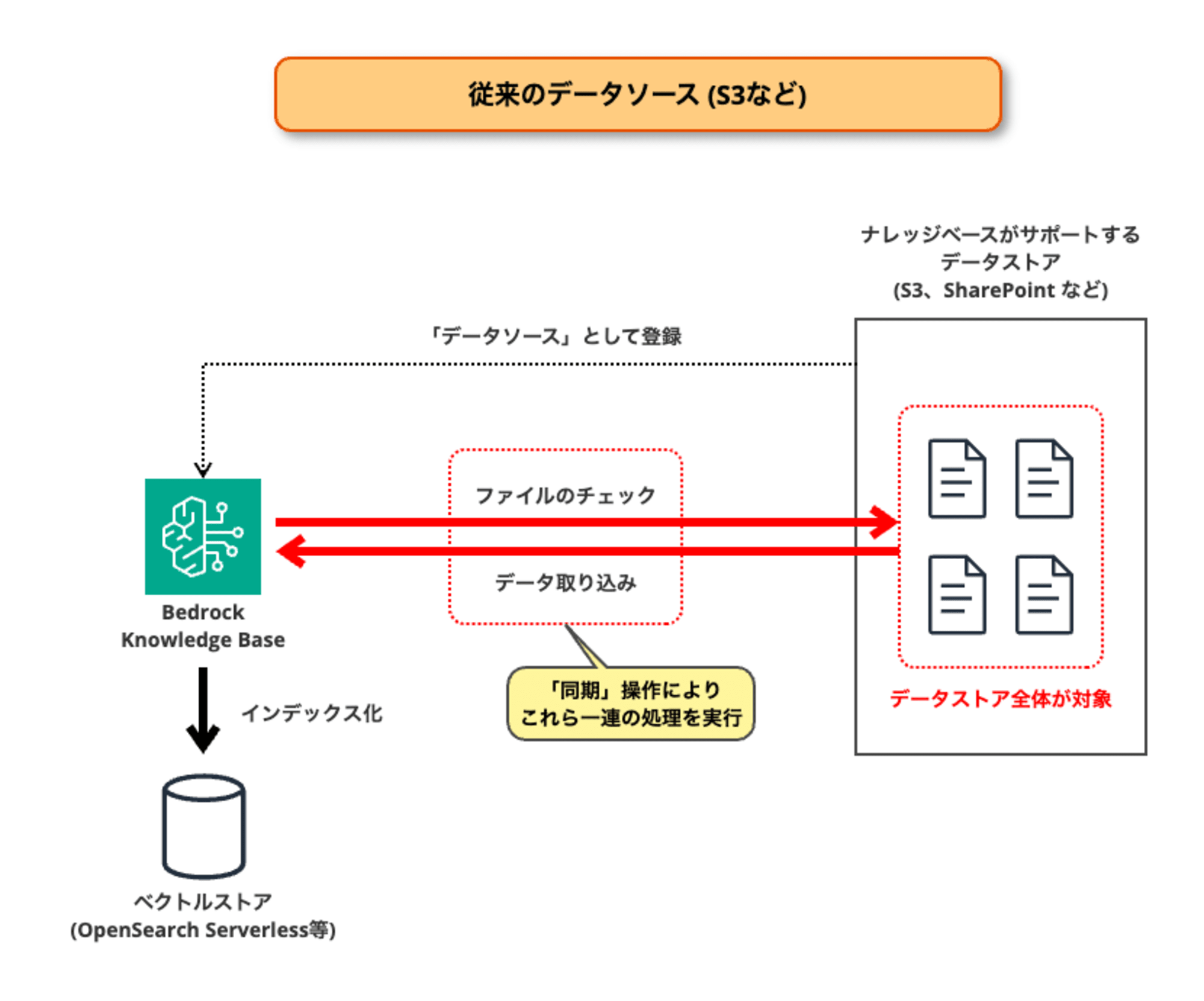
対象のデータストア (S3バケットなど) を予めナレッジベースに登録しておきます。
ナレッジベースで「同期」操作を行うことにより、データストア内のファイル群をナレッジベースに取り込み・インデックス化します。
ナレッジベース (Amazon Bedrockサービス) が直接データストアへアクセスすることになるため、IAMロール (AWSサービスロール) などによるアクセス権限の設定が必要です。
一方、今回の新機能「カスタムデータソース」は、下図のような構成・動作となります。
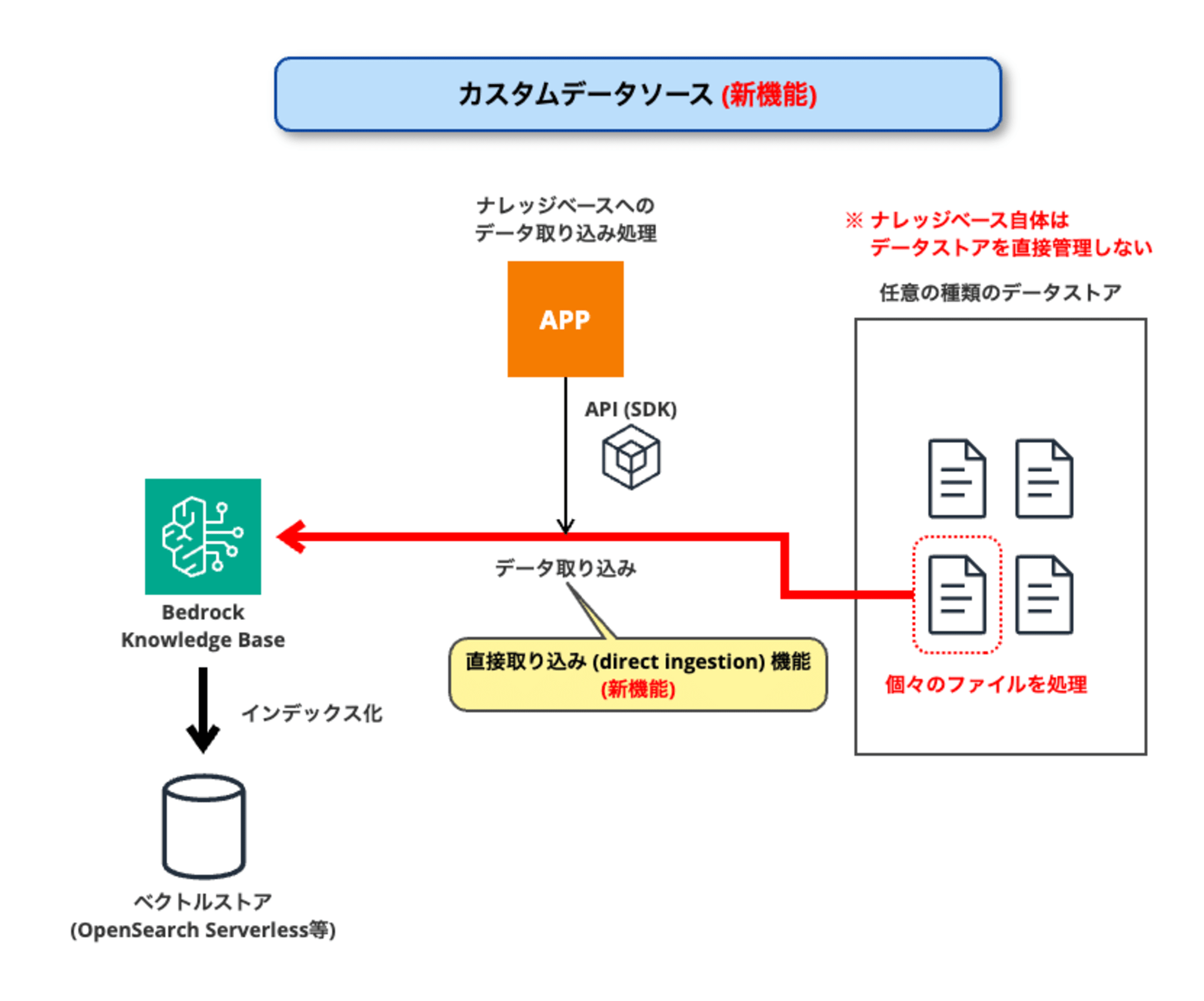
カスタムデータソースでは、データソースとなるデータストアをナレッジベースに登録するようなことはありません。(ナレッジベースの管理外)
データストア内のファイルを取り込む際は、ナレッジベース側から処理を開始するのではなく、Amazon Bedrockで提供されるAPI (SDK) を用いてアプリケーション等により取り込み処理を行う必要があります。
この時に行う取り込み処理が、今回のもう一つの新機能である「直接取り込み (direct ingestion)」です。
このように比較してみると、「カスタムデータソース」が従来のデータソースとは構成・動作が大きく異なることが分かります。
試してみる
それでは、実際に試してみましょう。
カスタムデータソースの作成
まずは、ナレッジベースに「カスタムデータソース」を作成します。
ナレッジベースの新規作成時にデータソースとして「カスタム」を選択することができますし、あるいは、作成済みのナレッジベースに「カスタムデータソース」を追加作成することも可能です。
いずれの場合も、データソースの選択画面で「Custom」を選択します。
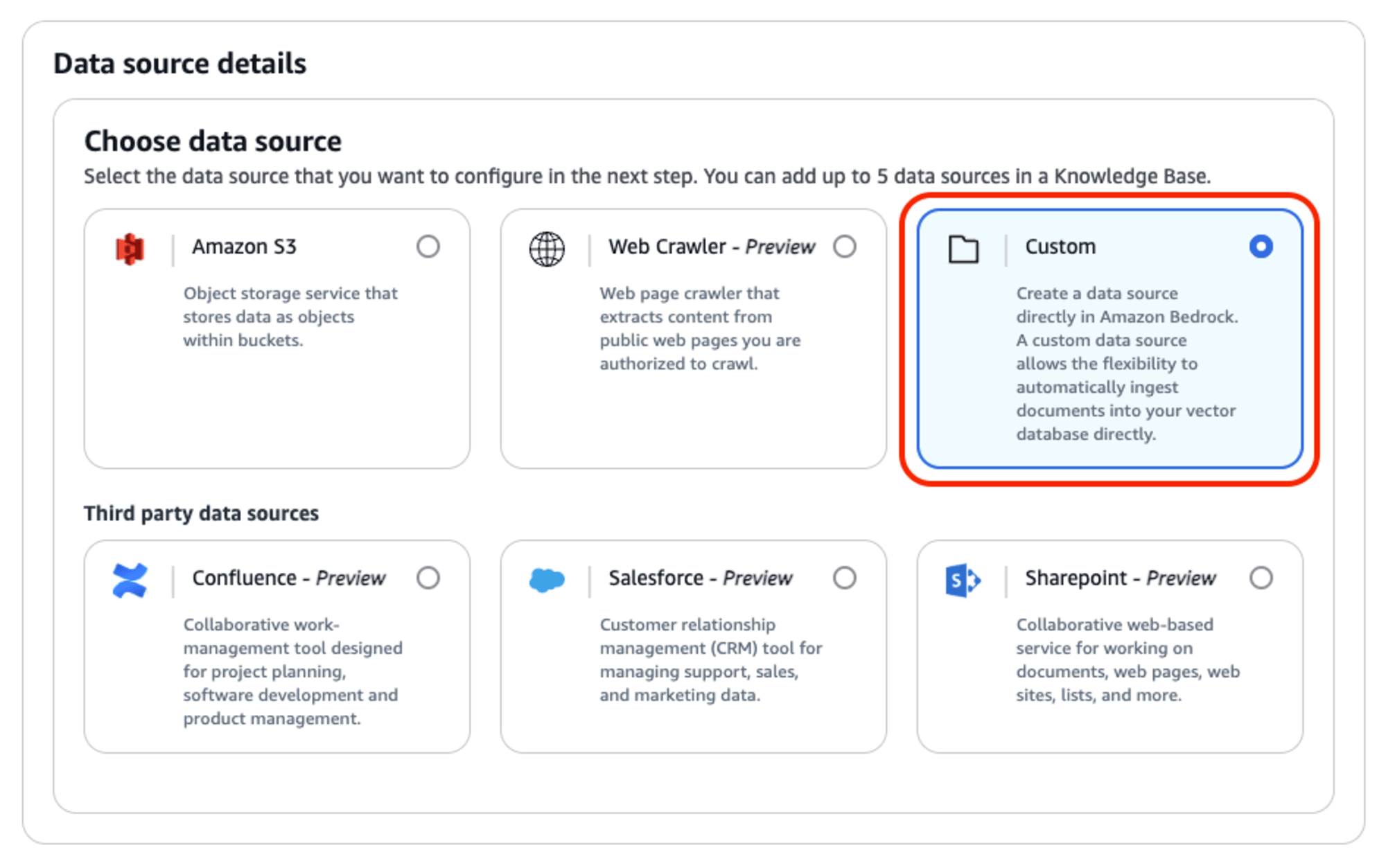
データソースの詳細を設定する画面では、他のデータソースのように「データソースの場所」「認証情報」などを入力する必要は無く、シンプルな設定項目となっています。
一方、他のデータソースと同様に「一時データストレージ用のKMSキー」や「チャンキング」「パーシング」の設定は存在します。
ドキュメントファイルの「直接取り込み」の実行
作成したカスタムデータソースに対して、手持ちのドキュメントファイルを取り込んでみましょう。
「直接取り込み」の実行手段には「API」「各種SDK」「AWS CLI」などの方法がありますが、まずはマネジメントコンソールを使って実行したいと思います。
ナレッジベースのプロパティ画面で、作成したカスタムデータソースを選択します。
カスタムデータソースのプロパティ画面になりますので、下部のドキュメント一覧の「Add documents」メニューをプルダウンして「Add document directly」を選択します。
取り込み対象のドキュメントファイルに関する情報を入力していきます。
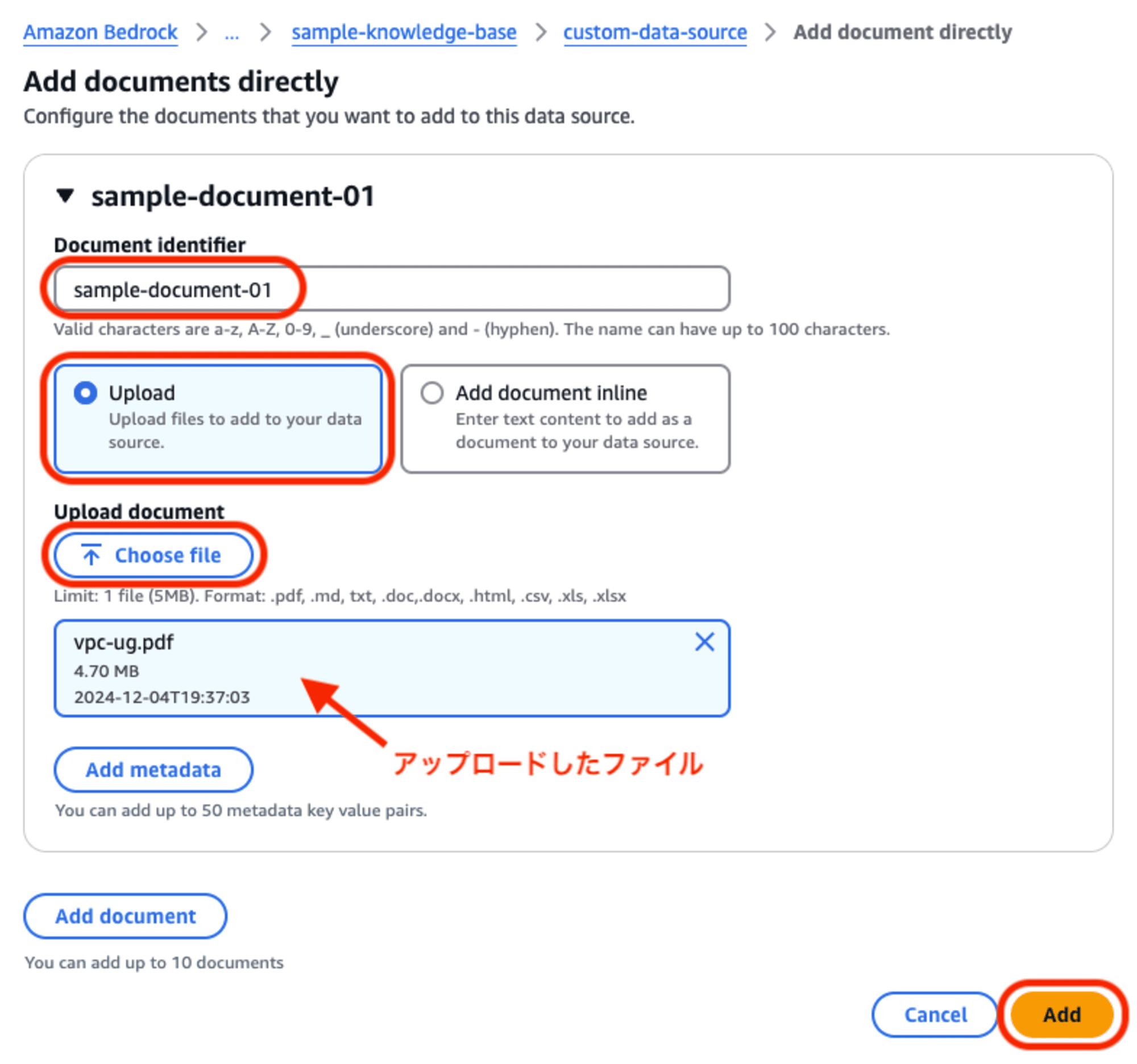
- Document identifier:
- 個々のドキュメントを特定する「識別子」を指定します。
- ファイル名などでも構いませんが、データソース内での重複ができませんので「フルパスにする」「タイムスタンプを付与する」等の工夫が必要です。
- Upload / Add document inline:
- ファイルの指定方法が2通りあります。ここでは「アップロード」を選択します。
- Upload document:
- 「Choose file」でファイル指定ダイアログを開いて、アップロードしたいファイルを選択します。
- 指定可能なファイルフォーマットはサポートされているドキュメント形式に準拠します。
- マネジメントコンソールを使ったアップロードでは、指定可能なファイルのサイズ上限が「5MB」であることに注意してください。(本来は50MBまで可能)
各項目を入力しましたら「Add」をクリックして登録します。
ドキュメントファイルを登録すると、自動的にナレッジベースへの取り込みが始まります。
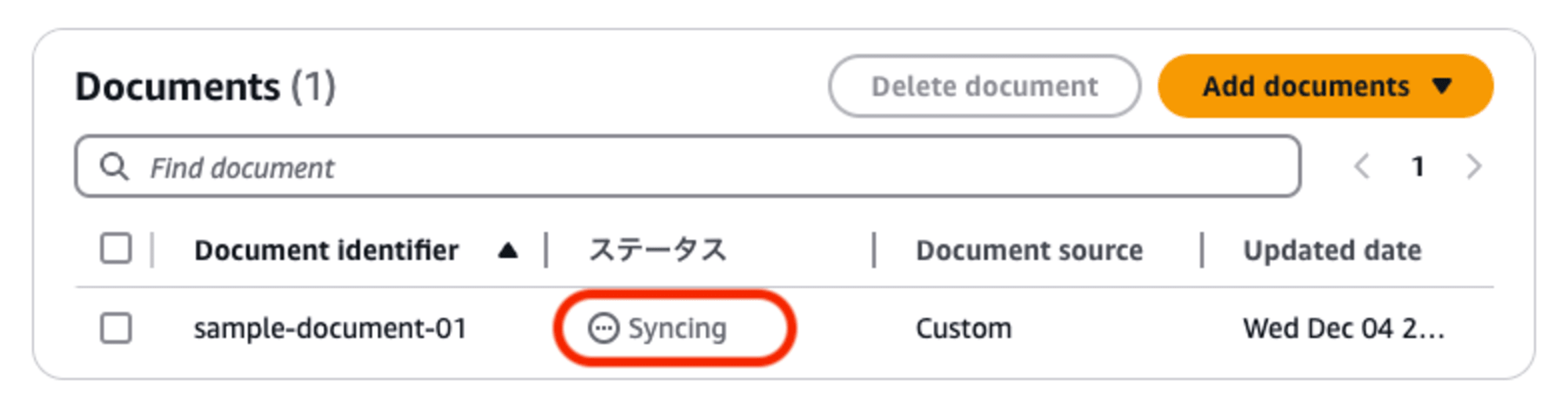
しばらくして、ステータス欄が「Success」になれば、取り込み処理の完了です。
ナレッジベースにデータを取り込めましたので、テストしてみましょう。
テスト画面で、使用したドキュメントに含まれている内容を質問してみます。
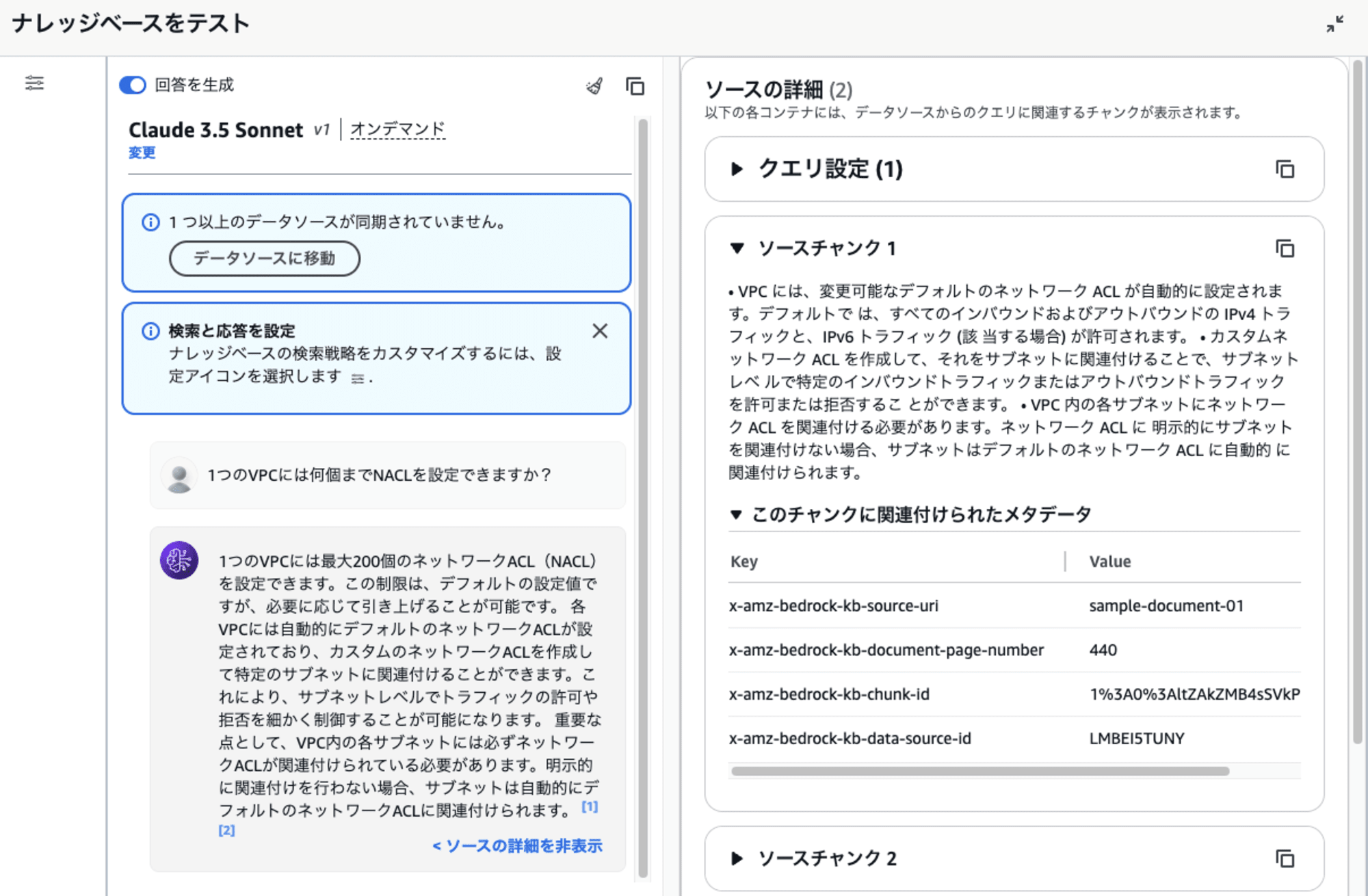
うん、ちゃんとカスタムデータソースに登録したデータを使って回答が生成されたようですね!
ドキュメントファイルの内容を直接投入する
さきほどの手順では、対象のドキュメントファイルをブラウザからアップロードしました。
しかし、APIやSDKを使ってデータ取り込みを実行する際には、ドキュメントファイルの内容 (テキストデータ/バイナリデータ) を直接指定する必要があります。
(「アップロード」オプションはマネジメントコンソールから機能を利用する際の利便性のために用意されたものです)
マネジメントコンソールからの操作でも、APIやSDKの利用時と同じようにテキストデータ/バイナリデータを直接指定してデータ取り込みを行うことができます。
実際にやってみましょう。
さきほどと同様に、カスタムデータソースのプロパティ画面で、下部のドキュメント一覧の「Add documents」メニューをプルダウンして「Add document directly」を選択します。
ドキュメントファイルの指定画面で、今度は「Add document inline」を選択します。
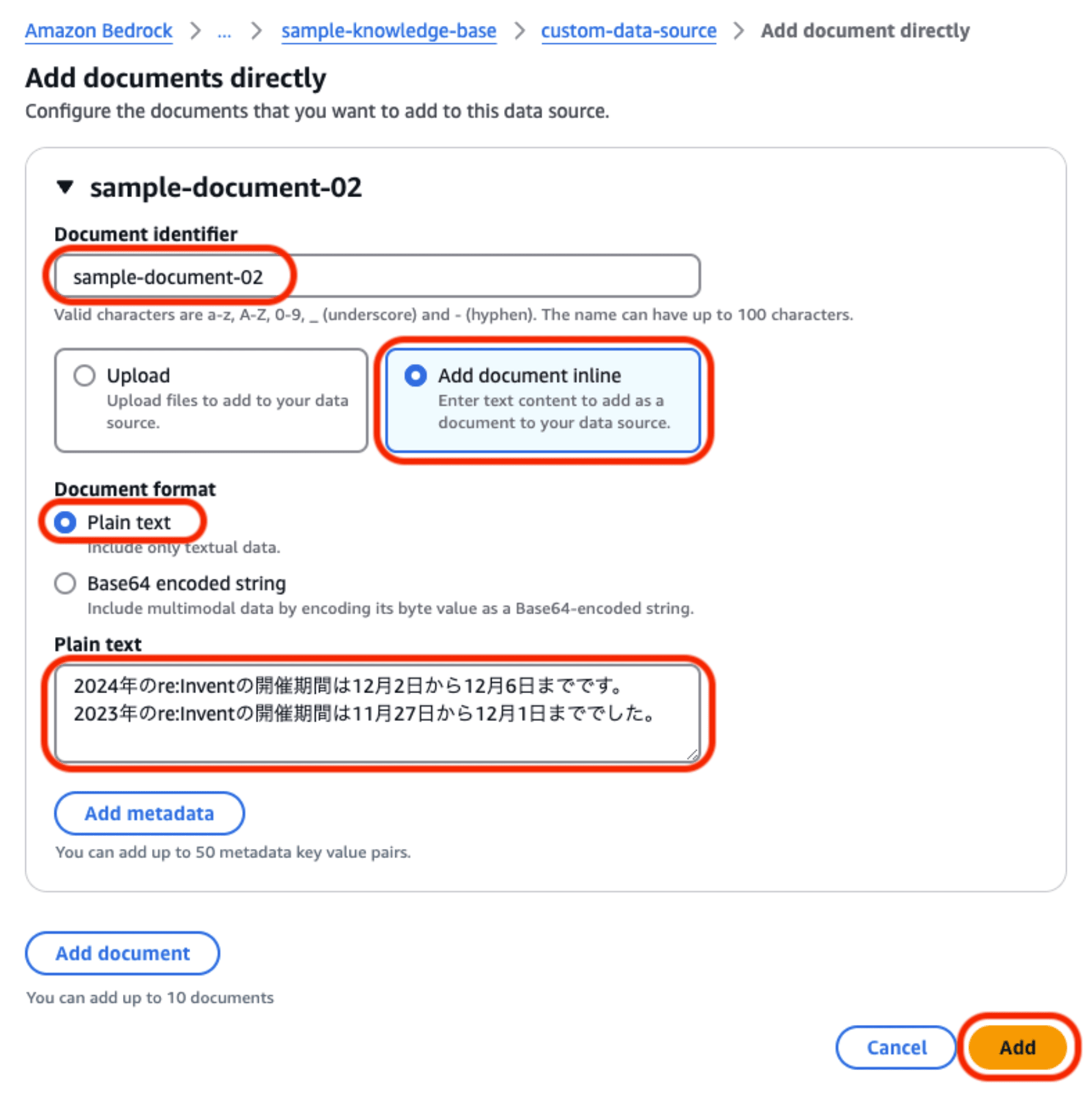
- Document identifier:
- 個々のドキュメントを特定する「識別子」を指定します。
- ファイル名などでも構いませんが、データソース内での重複ができませんので「フルパスにする」「タイムスタンプを付与する」等の工夫が必要です。
- Upload / Add document inline:
- ファイルの指定方法が2通りあります。ここでは「ドキュメントをインラインで追加」を選択します。
- Document format:
- 「Plain text」と「Base64 encoding string」の選択肢があります。今回は「プレーンテキスト」を選択します。
- Plain text:
- 取り込みたいデータ内容をテキストでそのまま入力します。
「Add」をクリックして、データの登録と取り込みを実行します。
データの取り込み処理が完了しましたら、テストしてみましょう。
どうですか? テキストで入力した内容に基づいて回答生成されましたでしょうか?
ちなみに、ドキュメント形式のもう一方の選択肢「Base64 encoding string」を選択した場合、対象のファイルをBase64エンコードした文字列を入力すればよいと思うのですが、私が試した限りでは上手くいきませんでした。(データ取り込み結果がFAILEDになってしまう)
バイナリデータの取り込みについては、後ほど、SDKを使った手順をご案内します。
S3を介したデータ取り込み
カスタムデータソースへのデータの「直接取り込み」には、ここまでで解説した「ドキュメントをインラインで追加」の方法のほかに、「S3を介した取り込み」の方法があります。
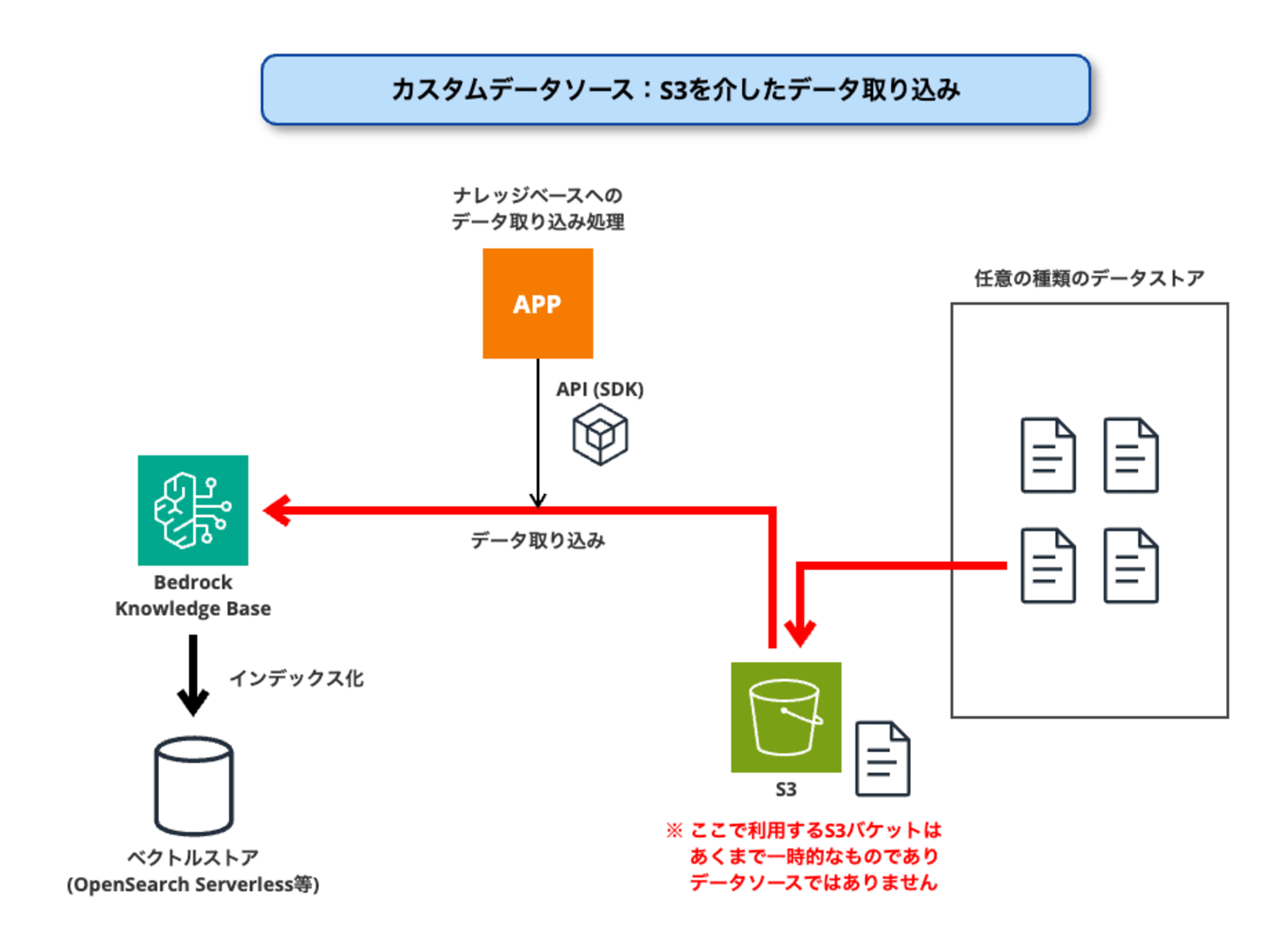
この方法は、以下の流れで行います。
- 対象ドキュメントファイルを、一旦「一時S3バケット」に置く
- ドキュメントファイルを置いた場所 (S3 URI) を指定して、データ取り込みを実行する
注意して欲しいのは、ここで使う「一時S3バケット」はあくまで一時的なものであり、「S3データソース」とは全く違うものであるという点です。
それでは、実際に試してみましょう。
既に「一時S3バケット」に対象ドキュメントファイルを配置している前提で進めます。
カスタムデータソースのプロパティ画面で、下部のドキュメント一覧の「Add documents」メニューをプルダウンして「Add S3 documents」を選択します。
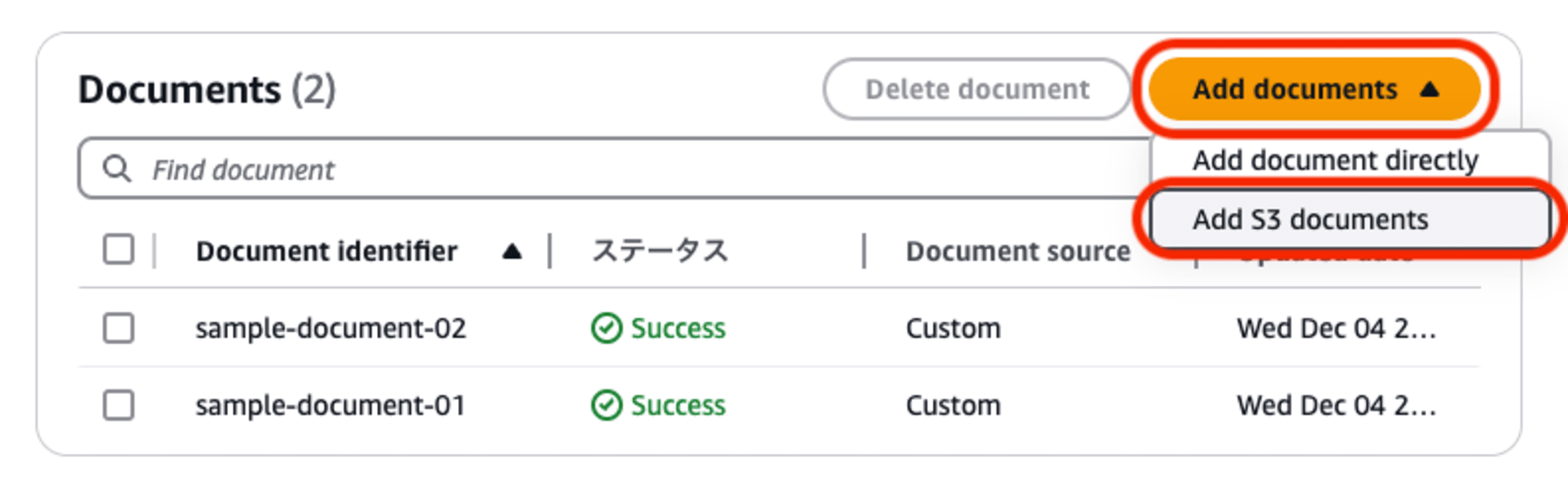
取り込み対象のドキュメントファイルが置かれている場所に関する情報を入力していきます。
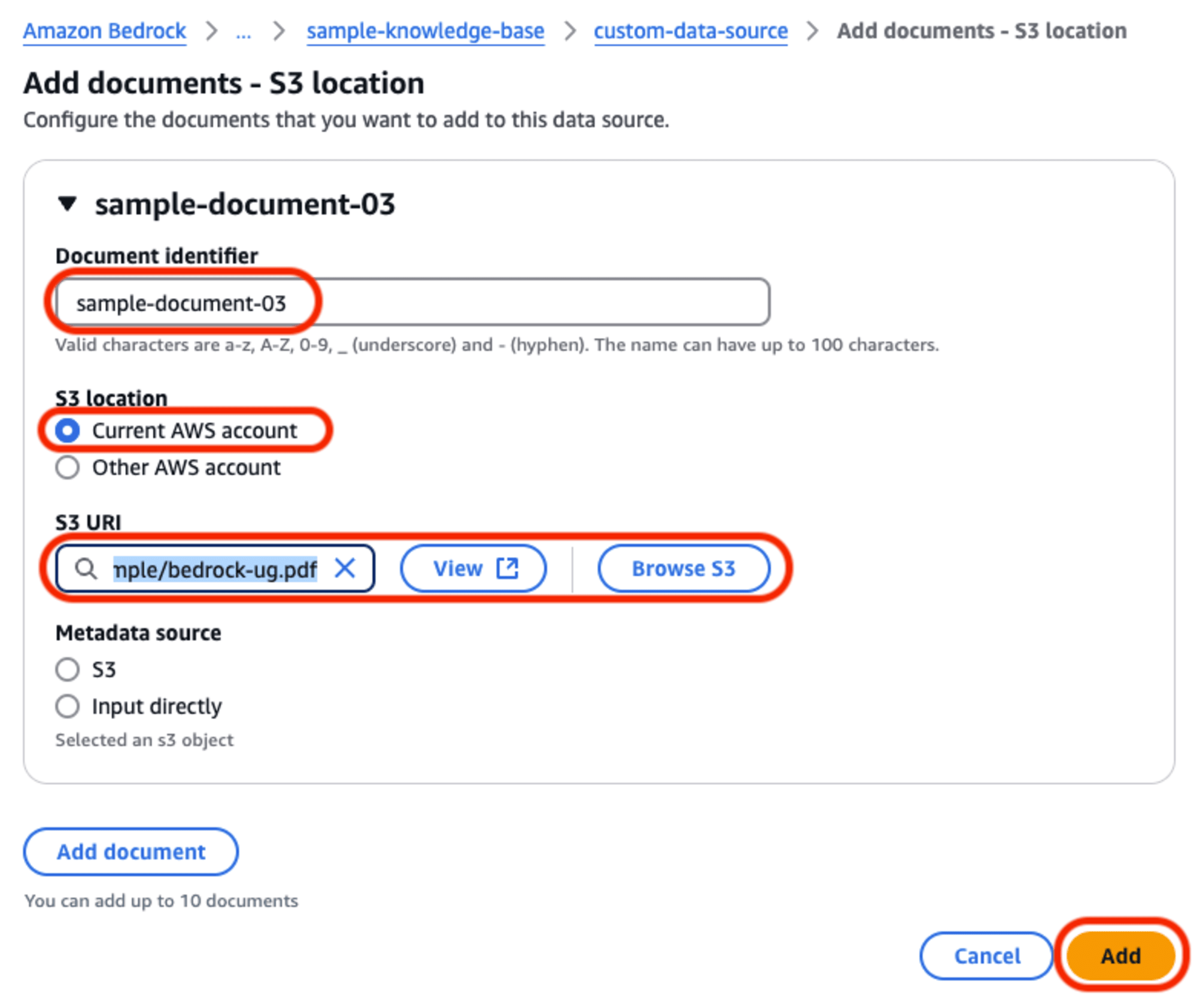
- Document identifier:
- 個々のドキュメントを特定する「識別子」を指定します。
- ファイル名などでも構いませんが、データソース内での重複ができませんので「フルパスにする」「タイムスタンプを付与する」等の工夫が必要です。
- S3 location:
- 「Current AWS account」と「Other AWS account」の選択肢があります。今回は「このAWSアカウント」を選択します。
- S3 URI:
- 一時S3バケットに配置したオブジェクト (ドキュメントファイル) のURIを指定します。
「Add」をクリックすると、データの登録と取り込みが行われます。
AWS SDK for Python (boto3) を使った実装
実際の運用を考えた場合、データソースのドキュメントファイルを手動で (マネジメントコンソールで) 取り込むというのは現実的ではありません。
したがって、API/SDKを使ったプログラムにより処理を行うことになります。
それぞれの取り込み方式におけるプログラムコードのサンプルを紹介します。
ドキュメントをインラインで追加 (テキストデータ)
コードは以下のようになります。
import boto3
import time
KNOWLEDGE_BASE_ID='<ナレッジベースID>'
DATA_SOURCE_ID='<データソースID>'
client = boto3.client('bedrock-agent', region_name='us-east-1')
def ingest_document_text(document_id, document_text):
response = client.ingest_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documents=[
{
'content': {
'dataSourceType': 'CUSTOM',
'custom': {
'customDocumentIdentifier': {
'id': document_id,
},
'sourceType': 'IN_LINE',
'inlineContent': {
'type': 'TEXT',
'textContent': {
'data': document_text,
},
},
},
},
},
],
)
return response
def check_status(document_id):
response = client.get_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documentIdentifiers=[
{
'dataSourceType': 'CUSTOM',
'custom': {
'id': document_id,
},
},
],
)
return response['documentDetails'][0]['status']
def main():
document_id = 'sample-document-01'
document_text = (
'2024年のre:Inventの開催期間は12月2日から12月6日までです。\n' +
'2023年のre:Inventの開催期間は11月27日から12月1日まででした。'
)
response = ingest_document_text(document_id, document_text)
while True:
status = check_status(document_id)
if status not in ['STARTING', 'IN_PROGRESS']:
print(f'The result of ingestion: {status}')
break
else:
print(f'Waiting for ingestion process. Current status is {status}.')
time.sleep(10)
if __name__ == "__main__":
main()
データの取り込みには ingest_knowledge_base_documents メソッドを使用します。
メソッドを呼び出すと、取り込み処理は非同期で行われ、完了を待たずにレスポンスが返ってきます。
そのため、処理ステータスを get_knowledge_base_documents メソッドでチェックする必要があります。
処理ステータス (下記以外にもあります):
STARTING: 開始中IN_PROGRESS: 取り込み処理実行中INDEXED: 処理成功 (インデックス化された)FAILED: 処理失敗
ドキュメントをインラインで追加 (バイナリデータ)
コードはテキストデータの場合とほぼ同じです。
import boto3
import time
KNOWLEDGE_BASE_ID='<ナレッジベースID>'
DATA_SOURCE_ID='<データソースID>'
client = boto3.client('bedrock-agent', region_name='us-east-1')
def ingest_document_binary(document_id, document_file_path, document_mime_type):
try:
with open(document_file_path, 'rb') as file:
bytes = file.read()
except Exception as e:
print(f'An error occerred: {e}')
return
response = client.ingest_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documents=[
{
'content': {
'dataSourceType': 'CUSTOM',
'custom': {
'customDocumentIdentifier': {
'id': document_id,
},
'sourceType': 'IN_LINE',
'inlineContent': {
'type': 'BYTE',
'byteContent': {
'mimeType': document_mime_type,
'data': bytes,
},
},
},
},
},
],
)
return response
def check_status(document_id):
response = client.get_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documentIdentifiers=[
{
'dataSourceType': 'CUSTOM',
'custom': {
'id': document_id,
},
},
],
)
return response['documentDetails'][0]['status']
def main():
document_id = 'sample-document-02'
document_file_path = './vpc-ug.pdf'
document_mime_type = 'application/pdf'
response = ingest_document_binary(document_id, document_file_path, document_mime_type)
while True:
status = check_status(document_id)
if status not in ['STARTING', 'IN_PROGRESS']:
print(f'The result of ingestion: {status}')
break
else:
print(f'Waiting for ingestion process. Current status is {status}.')
time.sleep(10)
if __name__ == "__main__":
main()
留意点としては、byteContent の要素として以下を指定する必要があります。
mimeType: ドキュメントファイルのフォーマットに応じたMIMEタイプを指定data: ドキュメントファイルの内容をバイトデータでセット
MIMEタイプの一覧は、AWS CLIのリファレンスに記載されています。
data にセットする値について、boto3のリファレンスでは「Base64でエンコードされた文字列」と記載されていますが、どうやらこれは間違いで、バイトデータを直接セットするのが正解のようです。
S3を介してドキュメントを取り込み
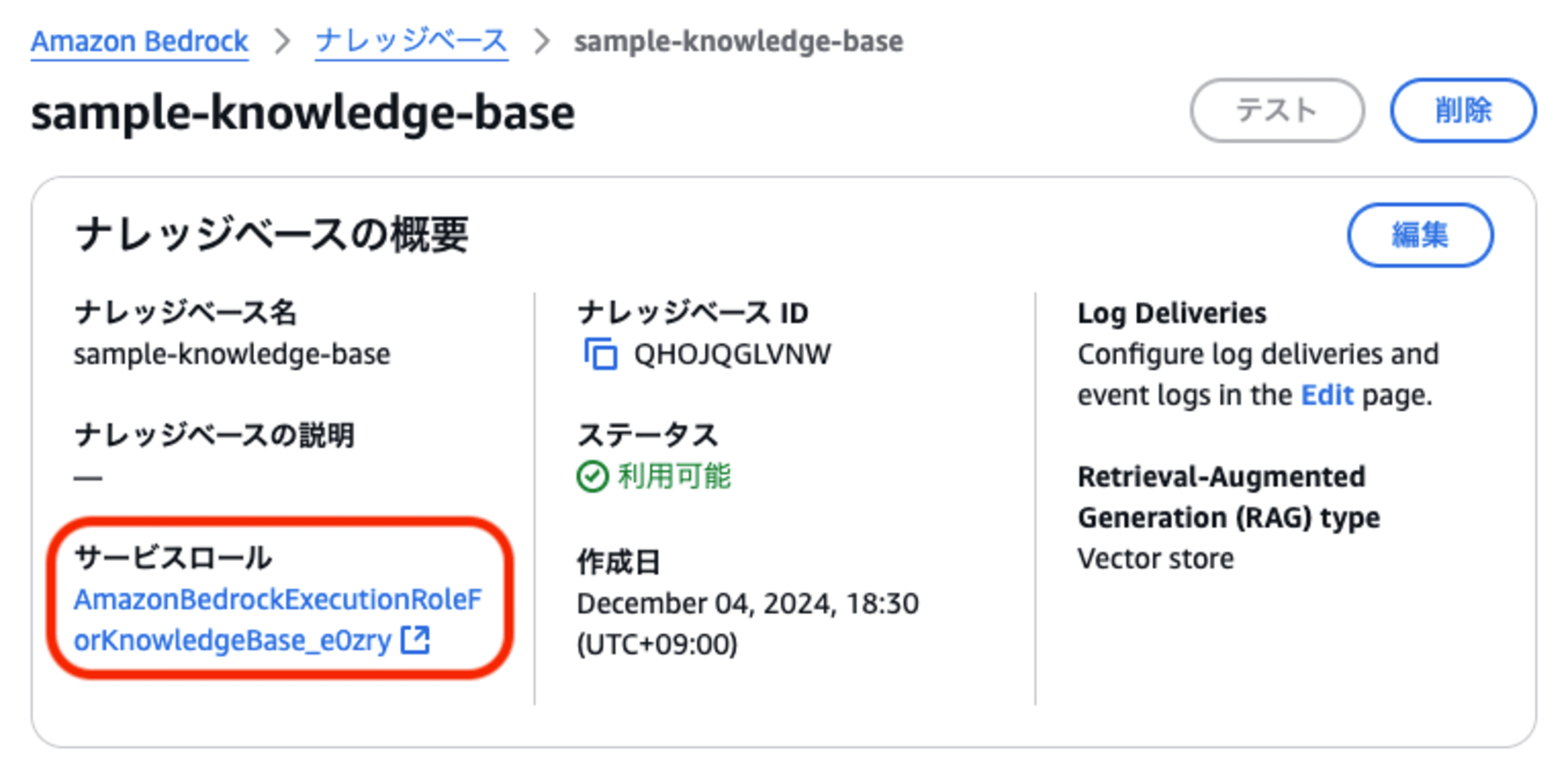
一時S3バケットに置いたドキュメントファイルを取り込む場合、処理を実行する前に「ナレッジベースからS3に対するアクセス権限」を設定する必要があります。
(なお、マネジメントコンソールから操作を行った際にアクセス権限の設定が不要だったのは、マネジメントコンソール操作の場合は自動的にサービスロールにポリシーが追加される仕様であるためです。API/SDKを使用する場合は明示的に設定する必要があります)
ナレッジベースの「サービスロール」に、以下のポリシーをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<一時S3バケットのバケット名>/*",
"Effect": "Allow"
}
]
}
※ サービスロールは、ナレッジベースのプロパティ画面で確認できます。
準備ができた後に、以下のコードを実行します。
import boto3
import time
KNOWLEDGE_BASE_ID='<ナレッジベースID>'
DATA_SOURCE_ID='<データソースID>'
client = boto3.client('bedrock-agent', region_name='us-east-1')
def ingest_document_s3(document_id, document_s3_uri):
response = client.ingest_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documents=[
{
'content': {
'dataSourceType': 'CUSTOM',
'custom': {
'customDocumentIdentifier': {
'id': document_id,
},
'sourceType': 'S3_LOCATION',
's3Location': {
'uri': document_s3_uri,
},
},
},
},
],
)
return response
def check_status(document_id):
response = client.get_knowledge_base_documents(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
dataSourceId=DATA_SOURCE_ID,
documentIdentifiers=[
{
'dataSourceType': 'CUSTOM',
'custom': {
'id': document_id,
},
},
],
)
return response['documentDetails'][0]['status']
def main():
document_id = 'sample-document-03'
document_s3_uri = 's3://<s3-bedrock-name>/bedrock-ug.pdf'
response = ingest_document_s3(document_id, document_s3_uri)
while True:
status = check_status(document_id)
if status not in ['STARTING', 'IN_PROGRESS']:
print(f'The result of ingestion: {status}')
break
else:
print(f'Waiting for ingestion process. Current status is {status}.')
time.sleep(10)
if __name__ == "__main__":
main()
隠れた機能追加(?) 「S3データソース」における「直接取り込み」機能
今回のアップデートは、新機能「カスタムデータソース」における「データの直接取り込み」に関するものですが、実は、既存の「S3データソース」に関しても1点アップデートがあります。
それは、S3データソースにおいても「データの直接取り込み」が行えるという点です。
Bedrock公式ドキュメントの「データの直接取り込み」ページに、以下のような表が掲載されています。

これによると、S3データソースにおいては「データの直接取り込み」機能のうち「ドキュメントをインラインで追加」は未サポートですが、「S3の場所を指定した取り込み」がサポートされるということです。
マネジメントコンソールからの操作イメージは以下の通りです。
S3データソースのプロパティ画面で、下部のドキュメント一覧の「Add documents」を選択します。
取り込み対象のドキュメントファイルが置かれている場所を指定します。
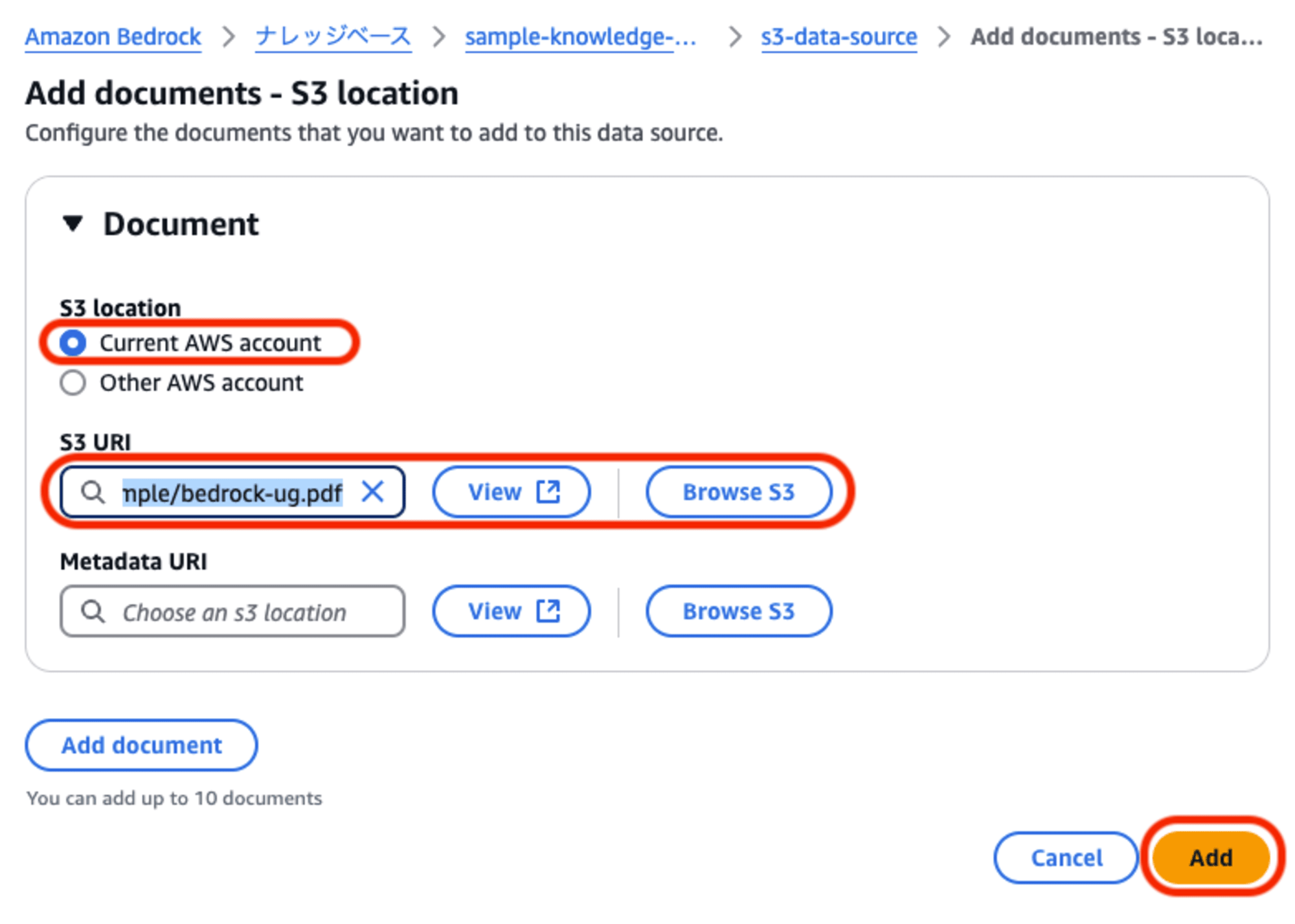
- S3 location:
- 「Current AWS account」と「Other AWS account」の選択肢があります。今回は「このAWSアカウント」を選択します。
- S3 URI:
- S3データソースに配置したオブジェクト (ドキュメントファイル) のURIを指定します。
注意点として、ドキュメントファイルを配置するのは、データソースとして登録したS3バケットにしてください。
操作上、データソース以外のS3バケットを指定することもできますが、データソースの管理上、ファイルが別々の場所にあると不整合が発生する恐れがあります。
さて、この「S3データストアにおける直接取り込み」機能ですが、カスタムデータソースにおける同機能とはちょっと位置付けが異なるのではないかと思っています。
S3データストアにおいては、従来の「同期」操作と、今回の新機能「直接取り込み」には以下のような違いがあります:
- 従来の「同期」操作: データストア全体をチェックして、追加・更新されたドキュメントファイルの取り込みを実行する。
- 新機能「直接取り込み」: ドキュメントを個別に指定して、そのファイルのみ取り込みを実行する。
こうやって対比すると、もはや「直接取り込み」というよりは「個別取り込み」と呼んだ方がイメージに合うかもしれません。
ファイルを個別に取り込めるのは利点があるような気もしますが、「同期」操作でも更新されたファイルのみが処理対象となるため、それほど使い勝手に差はないような気もします。(このあたりは要調査ですね)
おわりに
今回は、ナレッジベースの新機能「カスタムデータソース」と「直接取り込み (direct ingestion)」について、具体的な使い方を解説しました。
これらの機能を使えば、データソースコネクタが提供されていないデータストアであってもナレッジベースとの連係が行える可能性があります。
これまで、Bedrockを使ったRAG環境を構築する際、用意されているデータソースコネクタの豊富さからAmazon Kendraを採用する場面も多かったのではないかと思いますが、今後はナレッジベースも採用し易くなったのではないでしょうか。
なお、今回のブログ記事では紹介できませんでしたが、カスタムデータソースへ直接取り込みを行う際に、ドキュメントファイルと併せて「メタデータ」を取り込むことが可能です。
メタデータを取り込むことにより、より細かなデータソースの制御が可能になります。
機会があれば、次回は「メタデータ」取り込みについても解説したいと思います。









